
基于Scrapy的关键词式新闻爬虫
这是我闲鱼上接的第二个单子,既然做完了,那就干脆把项目开源吧。其实主要就是把之前写过的百度搜索爬虫改成了谷歌,又添加了几个新闻站点的解析。
心得体会
先来说一下心得体会,接这个单主要还是因为之前做过新闻爬虫,改起来也比较简单,这也是难得的不是爬微博的单子(真被微博搞怕了。。。),半年来愿者上钩一个单子也确实不容易。
这单子其实也不是那么省心,爬虫倒是早就写完了,把样例数据图表都给他看了也不鸟我,到最后,他自己论文来不及写了,急了,又跟我说做的图不符合他的要求。行啊,我也熬夜帮他改了,又说图表配色不好看,网站爬错了(我寻思你也没给我发过网址啊!我给你截图你也没说有问题)。我也算好说话了,数据都给你,你自己去画个统计图总行了吧,最后逼逼赖赖还是被砍了100。。。就当提前见识下无理甲方了呗。
但毕竟我这目的也不是为了赚钱,完成这项工作的过程中还是学到不少的。比如知道了谷歌搜索不管你首页显示搜到了多少条结果,其实最多只会显示1000条(百度只有750条),实际情况更少。而且谷歌的反爬机制还是挺强的,基本上爬了几百条结果就会触发验证码了,好在谷歌的镜像站比较多,可以换着用,被封的概率就小了很多了。
附 谷歌镜像站:
gogoo.ml
gug1.icu
此外,对于jieba库和matplotlib库的使用也是更熟练了。学习上的收获还是挺大的。
项目介绍
- 基于
Scrapy框架 - 谷歌高级搜索(爬取新闻链接)
- 关键词、站点自定义
- 新闻页面解析(已包含人民日报、纽约时报、东方新闻、星岛新闻页面解析)
- MySQL存储
- 数据分析(词云、词频等)
- 可拓展
目录结构
- 主体为Scrapy工程目录结构
utils目录下包括繁简转换插件,原项目地址analysis目录下为一些简单的数据分析代码,包括分词、词频统计等。spiders下包括谷歌搜索、人民日报、纽约时报、东方新闻、星岛新闻爬虫
如何使用
修改
settings.py中关于数据库的配置项1
2
3
4
5MYSQL_HOST = '127.0.0.1' # 数据库地址
MYSQL_DBNAME = 'job_news' # 数据库名称
MYSQL_USER = 'root' # 数据库账号
MYSQL_PASSWD = '123456' # 数据库密码
MYSQL_PORT = 3306启动谷歌搜索爬虫
1
scrapy crawl google -a kw=关键词 -a site=站点网址
启动新闻站点爬虫
1
scrapy crawl 爬虫名
demo展示
- 新闻目录

- 新闻内容

- 词云

- 词频
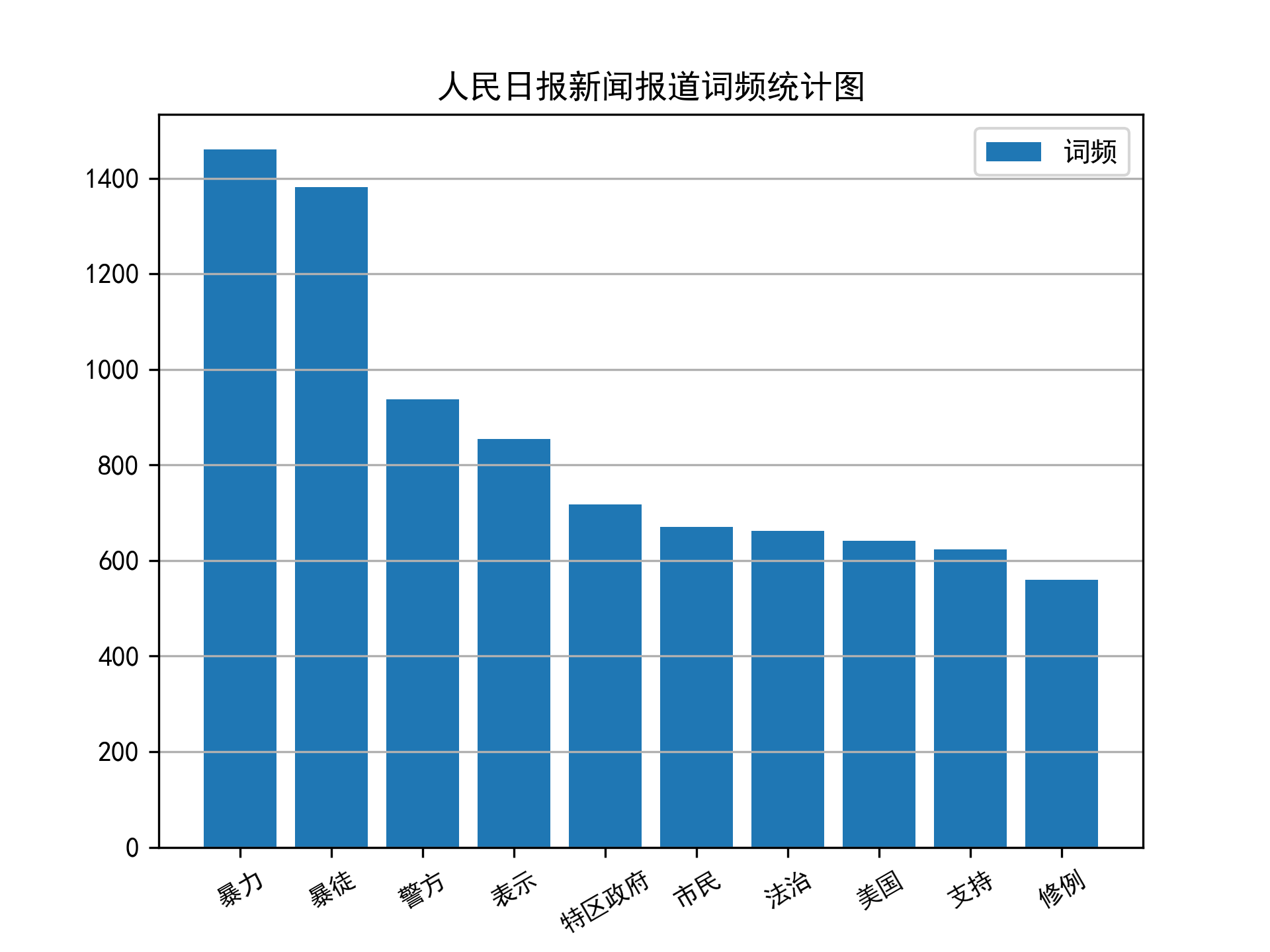
开发说明
新增新闻站点爬虫
在项目根目录执行:
1
scrapy genspider example example.com
仿照
peopleNews.py修改即可。

